
Building an accurate Retrieval-Augmented Generation (RAG)
14 July, 2025
Retrieval-Augmented Generation (RAG) has transformed how AI-driven systems provide accurate, contextually rich information. At Grey Chain, we have meticulously developed a sophisticated RAG system, leveraging cutting-edge multimodal ingestion, precise retrieval techniques, and reflective response generation to deliver unparalleled accuracy. Here’s how we’ve achieved this:
Part 1: Ingestion Pipeline – Multimodal Ingestion
Building a highly accurate RAG system begins with an exceptional ingestion process.
Specialized Document Ingestion
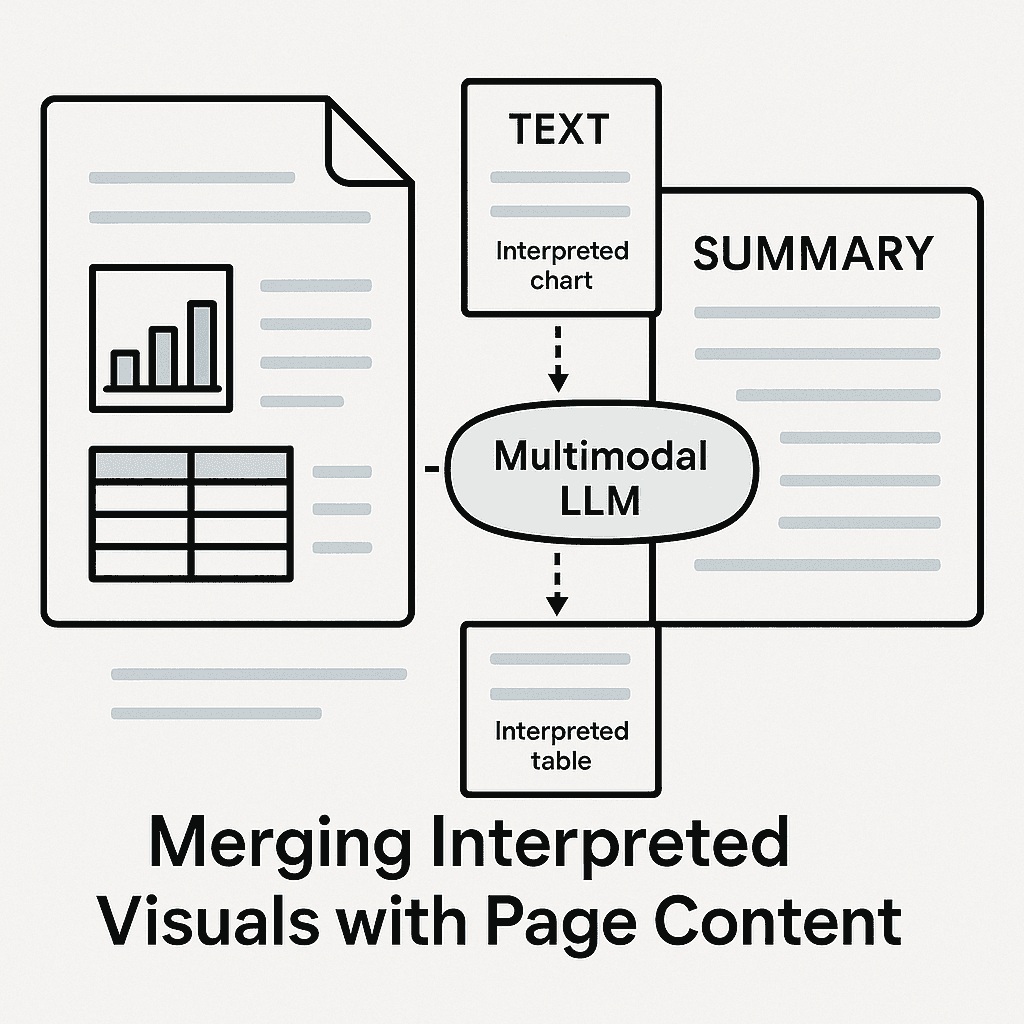
We have developed an advanced ingestion pipeline, uniquely handling each document. Every page ingested passes through a Multimodal LLM, adept at interpreting various forms of content—graphs, tables, and images. The model first generates a concise summary for each non-textual element, ensuring these elements are contextually understood.
Merging Interpretations
Post-interpretation, we carefully merge these visual summaries with the textual content, preserving the original order and context. This mimics human cognition—when we read, we intuitively understand visuals within the context of accompanying text.
Embedding and Storage
After merging, the refined content is segmented into chunks and converted into embeddings, subsequently stored within a vector database.
Sparse Embeddings: Capture keyword-level details and explicit information.
Dense Embeddings: Encode deeper semantic meanings and implicit relationships between concepts.
Utilizing both sparse and dense embeddings ensures that our system comprehensively understands and accurately represents complex information, from explicit details to nuanced meanings.
Chunk Overlapping for Continuity
Chunks are strategically overlapped to ensure seamless continuity across pages. This overlapping approach guarantees context remains intact, facilitating highly coherent and accurate retrieval later on.
Part 2: Retrieval
Effective retrieval is critical to RAG performance. Our ingestion pipeline ensures the content is richly embedded, allowing precise retrieval.
Embedding-based Retrieval
Retrieval initiates when a user submits a query. This query is converted into embeddings, and a cosine similarity metric is utilized to identify and retrieve chunks most semantically similar to the user's request. These chunks are then passed to the LLM for synthesis into an accurate response.
Enhanced Query Refinement
At Grey Chain, we differentiate by refining user queries before retrieval:
Query Correction: We automatically correct spelling mistakes or contextual mismatches in user queries.
Query Expansion: Generating several variations of the original query introduces additional relevant terminology, improving alignment with embedded content and yielding deeper, more comprehensive search results.
These enhancements dramatically improve retrieval relevance and response accuracy.
Part 3: Reflection
The final piece of our state-of-the-art RAG system is reflective validation.
Reflective Answer Validation
Once the LLM generates an answer, we validate it against the original query. If our reflection process identifies shortcomings or insufficient depth, it triggers additional retrieval rounds to provide the LLM with supplementary information.
This iterative reflection ensures the final output is both precise and contextually robust, significantly enhancing user satisfaction and trust in the system’s responses.
By integrating multimodal ingestion, precise retrieval methodologies, and reflective answer validation, Grey Chain’s RAG system delivers unmatched accuracy and understanding, truly representing state-of-the-art AI capabilities.